
本页面详细介绍了高可用性渲染器 (HAR) 的完整图形流水线,跟踪了从 Figma 设计文档到屏幕上显示的最终像素的数据流。
概览
该流水线将高级界面定义转换为低级图形命令,并高效地将其呈现在硬件显示屏上。该流水线专为汽车安全关键型应用而设计,强调确定性渲染、高效的状态管理以及与平台图形子系统(例如直接渲染管理器 (DRM) 和通用缓冲区管理 (GBM))的稳健交互。
该流水线可分为四个主要阶段:
- 预渲染: 处理场景图、应用自定义设置和解析布局。
- 命令生成: 将解析后的场景图转换为与后端无关的显示列表。
- 渲染: 使用 Impeller 图形引擎执行绘制命令。
- 呈现: 管理帧缓冲区并与显示硬件同步。
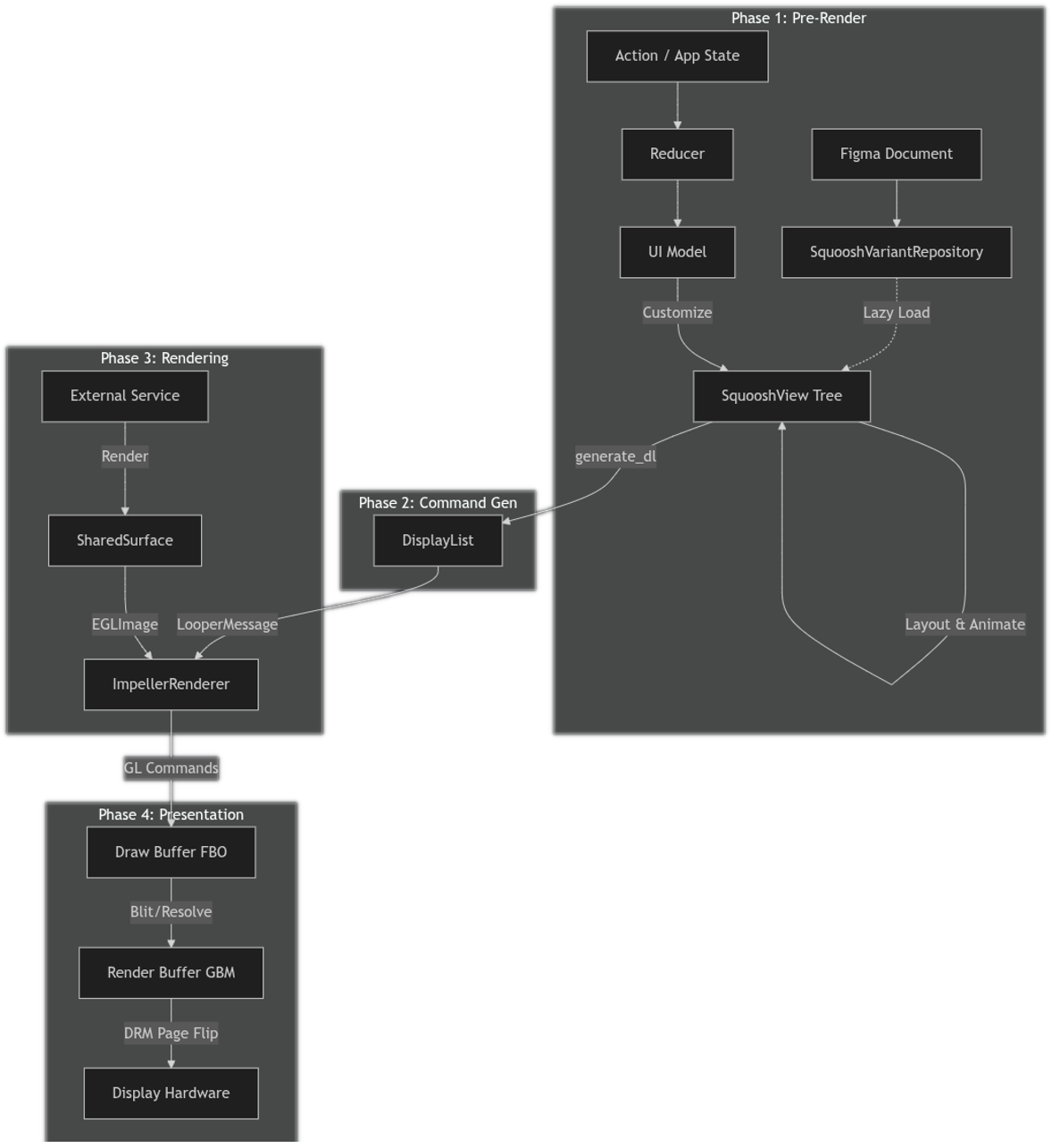
图 1. HAR 图形流。
第 1 阶段:预渲染
此阶段将静态 Figma 设计和动态应用状态转换为完全解析的内存界面树,以便进行渲染。此阶段在专用的缩减器线程上运行,与主显示循环分开。
1.1 DesignCompose 基础
HAR 流水线基于 DesignCompose 生态系统构建。
- 来源: 界面在 Figma 中设计,并使用 DesignCompose 插件导出。
- 定义: 输出是
DesignComposeDefinition的实例,它是设计的序列化表示形式(节点、样式、变体)。 - 数据绑定: 应用的界面模型使用过程宏(例如
#[Design(node = "#speed")])将 Rust 结构字段显式绑定到 Figma 文档中的特定命名节点。这样,应用状态就可以自动驱动视觉元素的属性。
此基础的关键组件包括:
- 缩减器: 充当中央事件循环,处理操作并更新当前状态。该框架提供
DefaultReducer,但如果需要,可以提供自定义缩减器实现。 - Presenter: 将当前状态桥接到界面模型。
Presenter特征由harry框架 crate 指定,并且在harry-app-corecrate 中提供了参考 实现 (UIModelPresenter)。 - 界面模型: 根据当前状态生成自定义设置。界面模型代码使用
derive_customizationscrate 提供的DesignDocument宏生成。harry-app-corecrate 中的UIModel结构提供了一个示例。 - Squoosh: 提供
SquooshView数据结构和变体存储库,用于根据设计渲染界面。序列化的设计文档由dc_bundlecrate 从 DesignCompose 库加载,并转换为SquooshView结构的树,以实现高效的运行时性能。
1.2 缩减器循环
流水线由操作驱动。该框架指定了 Actions 枚举类型,该类型定义了框架本身使用的内部操作,但还包含 CustomAction 变体,使用户能够定义其他应用专用操作(例如 UpdateVehicleSpeed 或 ButtonPress)。
该框架还提供了 StateAction 特征,该特征简化了影响应用状态的操作的实现,并可以选择生成副作用,然后从缩减器传递回应用以进行处理。harry-app-core crate 中的 CustomActions 枚举提供了一个详细示例。
以下是缩减器循环的基本概要:
- 操作处理:
Reducer接收操作并更新当前状态。这是原始数据,例如当前速度或哪些指示灯(警告灯)处于活跃状态。这还可能会产生副作用(例如,当安全带指示灯闪烁时,信号会播放提示音)。 - 呈现:
Presenter将新状态映射到UIModel。UIModel是一个视图模型,其中包含专门为界面格式化的数据(例如,将“120”速度格式化为字符串“65 mph”)。 - 自定义生成: 调用界面模型的
apply方法以生成一组RenderCustomization实例。这些是用于修改 Figma 设计的显式说明(例如,“将节点 #speed 的文本设置为‘65 mph’”)。 - 用于优化的
UpdatePolicy: 在每次预渲染传递后,系统都会返回UpdatePolicy值,指示何时需要进行下一次渲染更新。如果没有待处理的状态更改且没有动画正在运行,UpdatePolicy会发出信号,表明不需要立即进行进一步更新。在这种情况下,缩减器会停止生成新的显示列表,从而防止不必要的渲染周期并节省资源,直到新操作或事件触发更改。
1.3 视图提取和存储库初始化
流水线以 DesignComposeDefinition 实例开头。这是由 DesignCompose 序列化为协议缓冲区结构的 Figma 设计文档。
初始加载: 启动时,主设计(由其根节点指定)会从
DesignComposeDefinition转换为初始SquooshView树。这是一个一次性过程。存储库:
SquooshVariantRepository管理可重复使用的组件变体和最初加载的视图。延迟加载: 为了最大限度地缩短启动时间和减少内存用量,其他视图(不属于初始根节点树的视图)仅在渲染逻辑显式引用和需要时(例如,在列表自定义期间)才从文档中延迟加载。
1.4 自定义传递
遍历 SquooshView 树以应用动态应用状态:
变体交换: 根据运行时逻辑,组件实例会与特定变体交换(例如,将表示当前驾驶模式的图标从运动模式更改为经济模式)。
列表展开: Figma 中的单个模板项将替换为子项的动态列表。为这些子项生成新的唯一 ID,以验证动画的稳定身份。
文本和样式替换: 文本内容(例如速度值)和样式(例如不透明度、颜色)会根据当前状态进行更新。
1.5 变量解析
解析在 Figma 中或在应用本地定义的 Design 令牌和变量。
- 绑定: 引用变量(例如颜色或尺寸)的
SquooshView属性将替换为当前帧的具体值。
1.6 布局计算
动态布局:
DynamicLayout计算SquooshView树中每个节点的最终位置和大小(边界)。文本布局:
TextHelper使用LayoutHelper特征的实现来计算文本指标、换行和形状。这有助于在渲染之前验证文本是否在其约束范围内正确流动。
1.7 拨号盘和仪表
这是汽车界面的专用步骤。
MeterData:如果节点具有仪表数据(在 Figma 中定义),则其几何图形会根据meter_value(例如车速)动态更改。- 弧线: 扫描角度已调整。
- 旋转: 旋转转换根据起始角度和结束角度计算。
- 进度条: 矩形的宽度或高度会缩放。
- 进度向量: 向量路径的长度已调整。
1.8 动画
差异: 将当前
SquooshView与PreRenderCache中的previous_squoosh_view进行比较。插值: 如果属性已更改,
Squoosh会创建插值器,以便随时间平滑过渡值(例如不透明度或转换)。
第 2 阶段:命令生成
在 SquooshView 树完全解析并添加动画效果后,它会转换为绘制命令的线性序列。
此阶段的关键组件是 DisplayList crate:
generate_dl:此函数会递归遍历SquooshView树。翻译:
- 形状和路径: 转换为
DisplayListEntry,并使用相应的DisplayListAppearance变体(例如Rect或Path) - 文本: 使用
TextHelper转换为文本绘制条目。 - 转换和剪辑: 转换为
PushTransform3D和PopTransform3D或PushClipRegion和PopClipRegion对,以管理绘制状态堆栈。 - 遮盖: 转换为
PushMaskLayer和PopMaskLayer对,以正确创建和混合图层。
- 形状和路径: 转换为
最终结果是 Vec<DisplayListEntry> 的实例,它描述了 要绘制的内容
,而与 绘制方式 无关。
2.1 移交给 Looper
生成 DisplayList 后,缩减器会将其封装在 ViewDescriptor 的实例中,并通过 Rust MPSC 通道 (LooperMessage) 将其发送到 Looper 线程。Looper 负责渲染和显示阶段,这可防止缩减器线程阻止图形流水线。
第 3 阶段:渲染
与平台无关的 DisplayList 会移交给渲染后端,抽象命令会在其中转换为 GPU 指令。
HAR 使用 Impeller,这是一个最初为 Flutter 构建的渲染引擎。Impeller 旨在通过在构建时预编译一组小型高效的着色器来解决因着色器编译而导致的帧速率故障问题。这种方法与有效的批处理和高度优化的后端相结合,可提供:
- 确定性性能: 几乎消除了运行时着色器编译故障。
- 快速启动: 减少了初始化开销。
- 占用空间小: 生成紧凑的二进制文件大小。
如需全面了解 Impeller 的架构,请观看 Introducing Impeller - Flutter's new rendering engine。 虽然该视频讨论的是 Flutter,但这些核心优势直接为 HAR 汽车堆栈赋能。
渲染阶段的关键组件包括:
ImpellerRenderer:将预渲染阶段的显示列表转换为 Impeller 渲染命令。Impeller Rust API: 封装 Impeller 库以在 Rust 中使用 (
impeller和impeller-rs-bindgencrate)。TypographyContext:管理字体注册和文本形状。
3.1 初始化和 Surface 管理
上下文创建: 渲染器使用 OpenGL ES 后端初始化
impeller::Context的实例,并传递回调以从平台的 GL 上下文解析 OpenGL ES 函数指针。封装的 FBO Surface: Impeller 不会创建自己的窗口,而是渲染到第 4 阶段提供的现有 OpenGL 帧缓冲区对象 (FBO) 中。这是通过调用
Surface::create_wrapped_fbo完成的。
3.2 资源管理
图片: 支持标准格式和 KTX2 压缩纹理。这些内容会上传到 GPU 纹理,并由内部
Resources结构进行管理。字体: TrueType 和 OpenType 字体会加载并注册到
TypographyContext以进行文本渲染。外部图片: 外部纹理(例如相机 Feed 和外部 3D 渲染器)的专用处理涉及将
EGLImage实例或外部 OpenGL 纹理绑定到 ImpellerTexture对象,以实现零复制渲染。
3.3 渲染传递
render 循环使用 DisplayListBuilder 构建 Impeller DisplayList 实例(不要与预渲染阶段生成的 Vec<DisplayListEntry> 混淆):
清除缓冲区并应用全局转换以进行 DPI 缩放和显示旋转。
遍历输入
DisplayListEntry项:- 状态:
save()和restore()用于推送和弹出转换以及剪辑区域。 - 基元:
Rect和RoundedRect使用标准绘制 操作绘制。 - 路径: 构建和绘制复杂的向量路径(包括动态
Arc实例)。 - 文本:
Text和StyledText使用TypographyContext渲染。 - 图片: 使用
draw_texture_rect绘制标准图片和外部图片。
- 状态:
使用
surface.draw_display_list()将构建的 Impeller 显示列表提交到 Surface,生成底层 GL 命令。对底层上下文调用
swap_buffers()以触发第 4 阶段。
第 4 阶段:呈现
此最终阶段处理与显示硬件的交互,以显示渲染的帧。HAR 在 Android Automotive OS (AAOS) 软件定义车辆 (SDV) 上使用稳健的直接渲染路径。
此阶段的关键组件是 HarDirectRenderingContext(位于 har-gl-context crate 中)。
4.1 架构
呈现层使用双缓冲方法,并采用屏幕外绘制目标:
绘制缓冲区: Impeller 在其中渲染场景的屏幕外 FBO。
解析缓冲区(可选): 可选的辅助缓冲区,用于支持多重采样抗锯齿 (MSAA)
- 可以根据需要通过底层 OpenGL ES 实现或配置启用此功能。在这种情况下,它充当中间目标,用于在 blitting(位块传输)到渲染缓冲区之前解析多重采样的绘制缓冲区。
渲染缓冲区: 由 GBM 对象支持的通用缓冲区,对应于典型图形交换链中的后备缓冲区。
前端缓冲区: 扫描到显示屏的 GBM 缓冲区。
4.2 交换链
调用 swap_buffers 时,HAR 会执行以下步骤:
将绘制缓冲区的内容 blit 到渲染缓冲区(如果实现需要,则使用中间 blit 到解析缓冲区)。
对 GL 上下文调用
glFlush(),并创建EGL_SYNC_NATIVE_FENCE_ANDROID的实例以跟踪 GPU 完成情况。构建 DRM 原子请求,以将渲染缓冲区交换到屏幕。此请求包含 GPU 栅栏 FD(称为 in 栅栏),以防止显示控制器在 GPU 完成绘制之前显示渲染缓冲区。
同时向 DRM 请求新栅栏(称为 out 栅栏),以便在屏幕上不再显示上一个缓冲区(前一帧的前端缓冲区)时发出信号。
使用非阻塞标志提交原子请求,以使主线程能够继续运行,同时图形子系统保持同步。
将新的 out 栅栏存储在上下文中,以便 HAR 可以在后续帧的
swap_buffers进程开始时等待其发出信号。 这样可以防止 GPU 绘制到仍在显示的缓冲区。
4.3 直接模式设置
HAR 使用 DRM 和内核模式设置 (KMS) 子系统直接与内核交互,以配置显示分辨率 AAOS SDV,绕过与 SurfaceFlinger 等窗口管理器的交互(在特定配置中),从而实现对显示硬件的独占和高优先级控制。
4.4 外部渲染
HAR 支持将特定界面元素(由 Figma 中的标记标识)的渲染委托给外部进程或线程。这对于集成复杂的 3D 场景(例如来自 Kanzi 或 Unity 等引擎的自我车辆可视化)或其他需要专用 OpenGL 上下文的内容非常有用。
4.4.1 关键组件
HarExternalRenderContext:外部服务的专用屏幕外 EGL 上下文。SurfacePool:管理一组LocalSurface(Texture加EGLImage)缓冲区,用于双缓冲或三缓冲。SharedSurfaceExternalImage:用于在外部服务和主渲染器之间传递EGLImage句柄的线程安全封装容器。
4.4.2 工作流
工作流的顺序如下:
外部服务启动并向主 Looper 注册自身,标识其渲染的 Figma 标记(例如
#cluster/3d-car)。该服务等待来自 Looper 的
RenderStart信号,以使其渲染与显示的 VSYNC 信号保持一致。在屏幕外,该服务将其内容渲染到
SurfacePool提供的帧缓冲区中。该服务对其上下文调用
swap_buffers,这会旋转池并将完成的帧作为SharedSurface的实例提供。SharedSurface封装在ExternalImage中,并通过 Rust MPSC 通道发送到 Looper。主 Impeller 渲染器(第 3 阶段)接收外部图片。它不会复制像素数据,而是将底层
EGLImage直接绑定到纹理并将其绘制为主场景的一部分,从而实现零复制合成。
4.5 开发和测试平台 (har-platform-linux)
出于开发和测试目的,HAR 应用可以面向标准 Linux 桌面环境和无头设置。这些平台在 crates/reference/platforms/har-platform-linux crate 中实现。
与生产 AAOS SDV 目标不同,这些平台不使用 har-gl-context 的 direct-rendering 子系统进行显示输出。相反,它们依赖于标准 Rust OpenGL crate:
窗口模式: 使用
winit进行窗口管理和事件循环,使用glutin创建 OpenGL ES 上下文并与窗口系统集成。无头模式: 使用
har-gl-contextcrate 创建具有默认 EGL 显示屏的屏幕外 pbuffer 上下文。这样就可以渲染到屏幕外缓冲区,而无需可见窗口或直接显示硬件访问,主要用于自动化测试或后端处理。