
Konfiguracje danych określają kampanie telemetryczne, które są uruchamiane przez usługę Telemetry. Konfiguracja wskaźników to instancja MetricsConfigkomunikatu bufora protokołu (protobuf). Konfiguracje danych określają sposób zbierania, przetwarzania i raportowania danych. Producenci OEM mogą aktywować konfiguracje danych za pomocą interfejsu API usługi telemetrycznej. Wiele konfiguracji może działać jednocześnie.
Zanim zaczniesz, zapoznaj się z architekturą SDV, która jest architekturą zorientowaną na usługi, w której usługi publikują dane w postaci komunikatów protobuf. Te wiadomości komunikują się za pomocą stosu komunikacyjnego SDV przez RPC lub publikowanie i subskrybowanie.
Kluczowe terminy
Konfiguracja wskaźników koordynuje zbieranie danych przez określanie źródeł danych, reguł przetwarzania i mechanizmów raportowania. Jedną z głównych zalet przetwarzania na urządzeniu jest ograniczenie mobilnej transmisji danych. Przetwarzając dane o wysokiej częstotliwości na urządzeniu i przesyłając do chmury tylko dane zbiorcze lub statystyki, możesz znacznie zmniejszyć ilość przesyłanych danych.
Definicja konfiguracji danych zaczyna się od wymienienia źródeł danych, które mają być używane w konfiguracji. Są to usługi, które udostępniają dane za pomocą stosu komunikacyjnego SDV. Gdy aktywujesz konfigurację, usługa Telemetria łączy się z tymi źródłami, aby w razie potrzeby przesyłać strumieniowo lub pobierać dane.
Podstawą konfiguracji jest możliwość przetwarzania danych na urządzeniach brzegowych, zarządzana za pomocą stanowych agregatorów danych. Każdy agregator używa konstruktora wiadomości, który utrzymuje instancję wiadomości proto z informacjami o stanie. Każde pole w tym komunikacie jest wypełniane przez obliczenie wyrażenia, które określa, jakie dane mają być odczytywane z innych źródeł danych lub agregatorów, oraz jakie operacje matematyczne, logiczne lub agregacyjne mają być stosowane do tych danych. Do wyniku wyrażenia możesz zastosować dodatkowe agregacje.
Kluczową rolę w kontrolowaniu tego procesu odgrywają wyzwalacze. Mogą one być uruchamiane okresowo, w odpowiedzi na nowe dane lub po spełnieniu warunków opartych na danych. Wywołania określają, kiedy agregatory oceniają narzędzie do tworzenia wiadomości i kiedy generowane są raporty o danych. Mogą też wpływać na cykl życia konfiguracji, np. rozpoczynając lub zatrzymując zbieranie danych.
Ostatecznym wynikiem są raporty dotyczące danych. Każdy raport zawiera ładunek danych zdefiniowany przez narzędzie do tworzenia wiadomości oraz metadane, takie jak sygnatury czasowe i identyfikator raportu. Raporty możesz generować w określonych momentach cyklu życia konfiguracji, np. gdy konfiguracja jest aktywowana lub dezaktywowana. Wygenerowane raporty są przechowywane w pamięci, a klient jest powiadamiany o możliwości ich pobrania za pomocą kanału powiadomień o stanie raportu.
Na ilustracji poniżej przedstawiono przykładowy sposób interakcji komponentów w konfiguracji wskaźników:
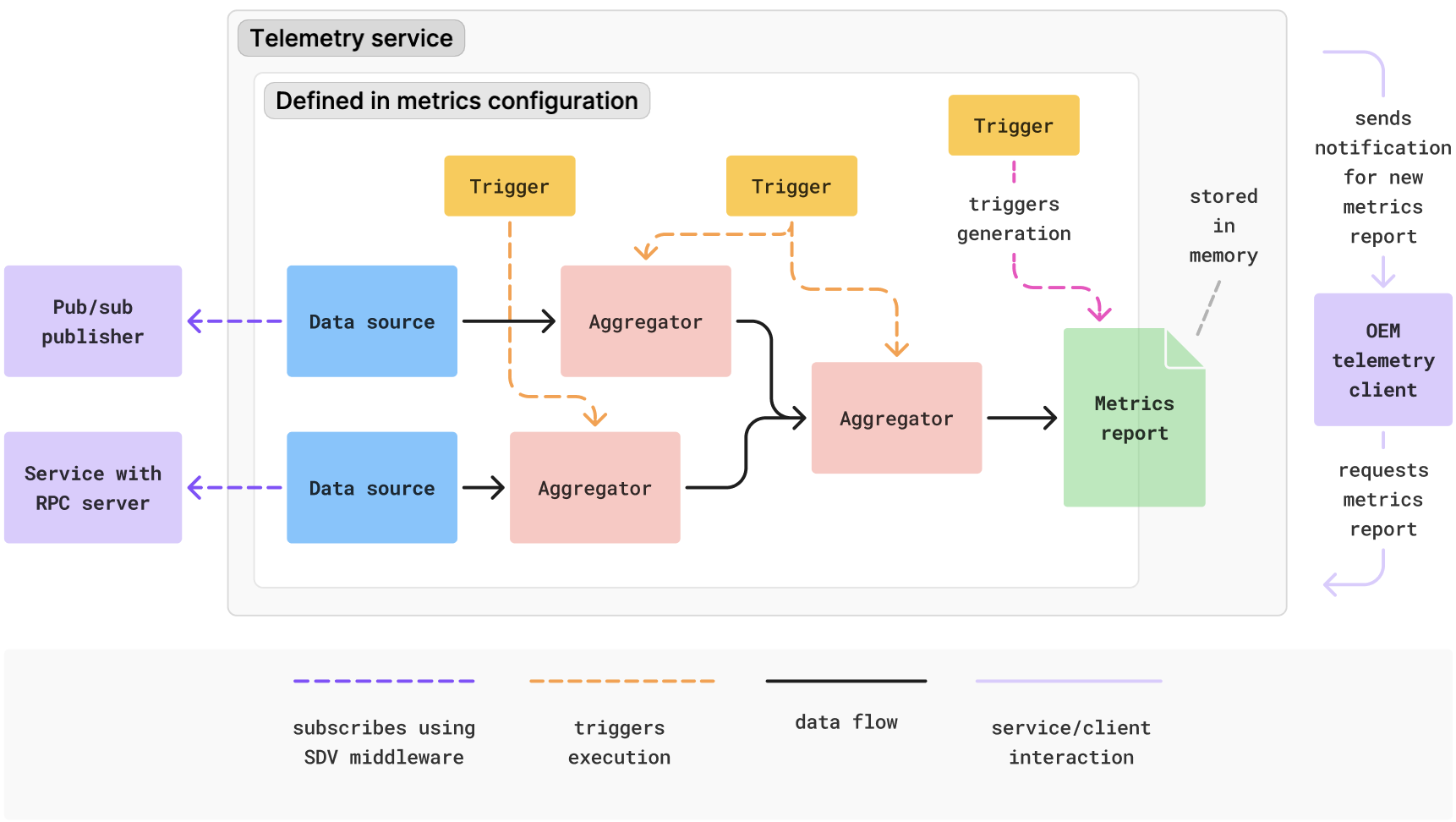
Rysunek 1. Źródła danych, przetwarzanie i raportowanie w konfiguracji danych.
Komponenty konfiguracji wskaźników
Konfiguracje danych umożliwiają definiowanie zadań zbierania danych i złożonych potoków przetwarzania na urządzeniu. W tej sekcji opisujemy główne komponenty używane do definiowania kampanii opartej na danych. Komponenty są przedstawione w kolejności, w jakiej dane przepływają przez system, od danych wejściowych do wyjściowych. Możesz zdefiniować te komponenty w dowolnej kolejności. Przetwarzanie danych za pomocą agregatorów i zarządzanie cyklem życia są opcjonalne.
- Definiowanie źródeł danych
- Przetwarzanie danych za pomocą agregatorów
- Sterowanie przepływem wykonywania za pomocą wyzwalaczy
- Generowanie raportów o danych
- Zarządzanie cyklem życia zbierania danych
Definiowanie źródeł danych
Podstawą każdej kampanii opartej na statystykach są dane. W konfiguracji danych o pomiarach mechanizm odbierania danych jest abstrakcyjny. Musisz tylko podać nazwę, pod którą można zidentyfikować źródło danych, oraz tryb połączenia (subskrypcja lub na żądanie). Źródłami danych mogą być dowolne usługi, które udostępniają dane za pomocą stosu komunikacyjnego SDV lub rejestrują się w rejestrze wydawców z możliwością konfiguracji, co umożliwia zbieranie danych z aplikacji, w których oprogramowanie pośredniczące SDV jest niedostępne. Każde źródło danych musi mieć w konfiguracji unikalną nazwę, aby można było się do niego odwoływać w innych komponentach konfiguracji danych, takich jak wyzwalacze czy agregatory. Możesz skonfigurować sposób łączenia się, częstotliwość otrzymywania danych i podać obiekt konfiguracji specyficzny dla usługi.
Konfiguracja źródeł danych
Usługa telemetrii może połączyć się ze źródłem danych na 2 sposoby:
- Getter: ta metoda pobiera dane na żądanie, gdy wyrażenie zdefiniowane w konfiguracji danych musi odczytać dane z tego źródła. Jest to przydatne w przypadku źródeł danych, które nie zapewniają ciągłego strumienia danych, lub gdy potrzebujesz rzadkich zrzutów danych.
- Subskrypcja: jest to domyślna metoda. Ustanawia ciągły strumień danych ze źródła. Ten typ połączenia jest wymagany, jeśli chcesz używać wyzwalacza danych, który uruchamia się, gdy z tego źródła przychodzą nowe wiadomości.
W przypadku subskrypcji możesz skonfigurować:
- Podpróbkowanie: aby uniknąć zbyt częstego pozyskiwania danych, możesz określić minimalny odstęp czasu między kolejnymi wiadomościami z tego samego źródła. Jeśli źródło publikuje dane szybciej niż w tym przedziale, usługa telemetrii ogranicza liczbę powiadomień, a wyzwalacze danych są aktywowane tylko w przypadku wiadomości otrzymanych po ograniczeniu. W ten sposób skutecznie zmniejszasz próbę danych.
- Pobieranie początkowej wiadomości: możesz skonfigurować usługę tak, aby po utworzeniu subskrypcji pobierała z źródła najnowszą wiadomość. Dzięki temu źródło danych jest od razu wypełniane wartością, jeśli jest ona dostępna, zamiast czekać na opublikowanie pierwszej nowej wiadomości. Jest to przydatne w przypadku wyzwalaczy warunkowych lub agregatorów, które wymagają stanu początkowego, lub gdy źródło danych publikuje informacje rzadko.
Niezależnie od typu wiadomości są buforowane wewnętrznie. Jeśli wiele wyrażeń lub agregatorów wymaga danych z tego samego źródła w jednym cyklu oceny, system pobiera dane tylko raz – z pamięci podręcznej, jeśli nowy komunikat dotarł w ramach subskrypcji, lub za pomocą pojedynczego wywołania na żądanie.
Przetwarzanie danych za pomocą agregatorów
Źródła danych dostarczają nieprzetworzone dane, a agregatory przeprowadzają stanowe przetwarzanie danych na urządzeniach brzegowych. Pobierają dane ze źródeł danych lub innych agregatorów, przekształcają je i udostępniają wyniki do odczytu w raportach o danych lub do dalszego przetwarzania przez inne agregatory. Umożliwia to tworzenie wieloetapowych potoków przetwarzania, np. obliczanie statystyk prędkości w jednym agregatorze i używanie tych statystyk w innym komponencie, który wykrywa wzorce zachowań podczas jazdy.
Agregatory są uruchamiane do wykonywania obliczeń przez co najmniej 1 regułę. Za każdym razem, gdy zostanie uruchomiona jedna z jego reguł, agregator ocenia swoje reguły i aktualizuje swój stan wewnętrzny.
Możesz skonfigurować agregator tak, aby resetował swój stan po odczytaniu jego wartości przez inny komponent. Jest to przydatne do obliczania statystyk w niepokrywających się okresach.
Kreator wiadomości określa strukturę i logikę agregatora. Konstruktor wiadomości określa, jak utworzyć instancję wiadomości proto, opisując sposób generowania danych dla każdego z jej pól. Dla każdego pola wyrażenie określa, jak odczytywać dane ze źródeł danych i agregatorów oraz jak stosować do nich operacje. Możesz też zastosować agregację, czyli operację obliczeniową lub operację na zbiorach, która jest stosowana do wyników wyrażenia w czasie.
Obsługiwane są te typy agregacji:
- Matematyczne: oblicza statystyki (średnią, minimum, maksimum, sumę, odchylenie standardowe i różnicę) na podstawie wartości zwracanych przez wyrażenie przy każdym wywołaniu. Delta to różnica między bieżącą a poprzednią wartością liczbową zwróconą przez wyrażenie.
- Lista: zbiera wartości zwracane przez wyrażenie na liście. Możesz ograniczyć rozmiar listy, aby utworzyć okno przesuwne (bufor pierścieniowy) z ostatnimi wartościami.
- Liczba: przypadek specjalny, w którym nie określono wyrażenia. Zlicza, ile razy pole jest oceniane (czyli ile razy jest wywoływany agregator lub raport).
- Przekazywanie: bezpośrednio wykorzystuje wynik wyrażenia bez stosowania agregacji. Jest to przydatne w konfiguracjach raportów do uzyskiwania dostępu do wartości końcowych z agregatorów.
Poniższy rysunek to schemat koncepcyjny ilustrujący ocenę agregatora:
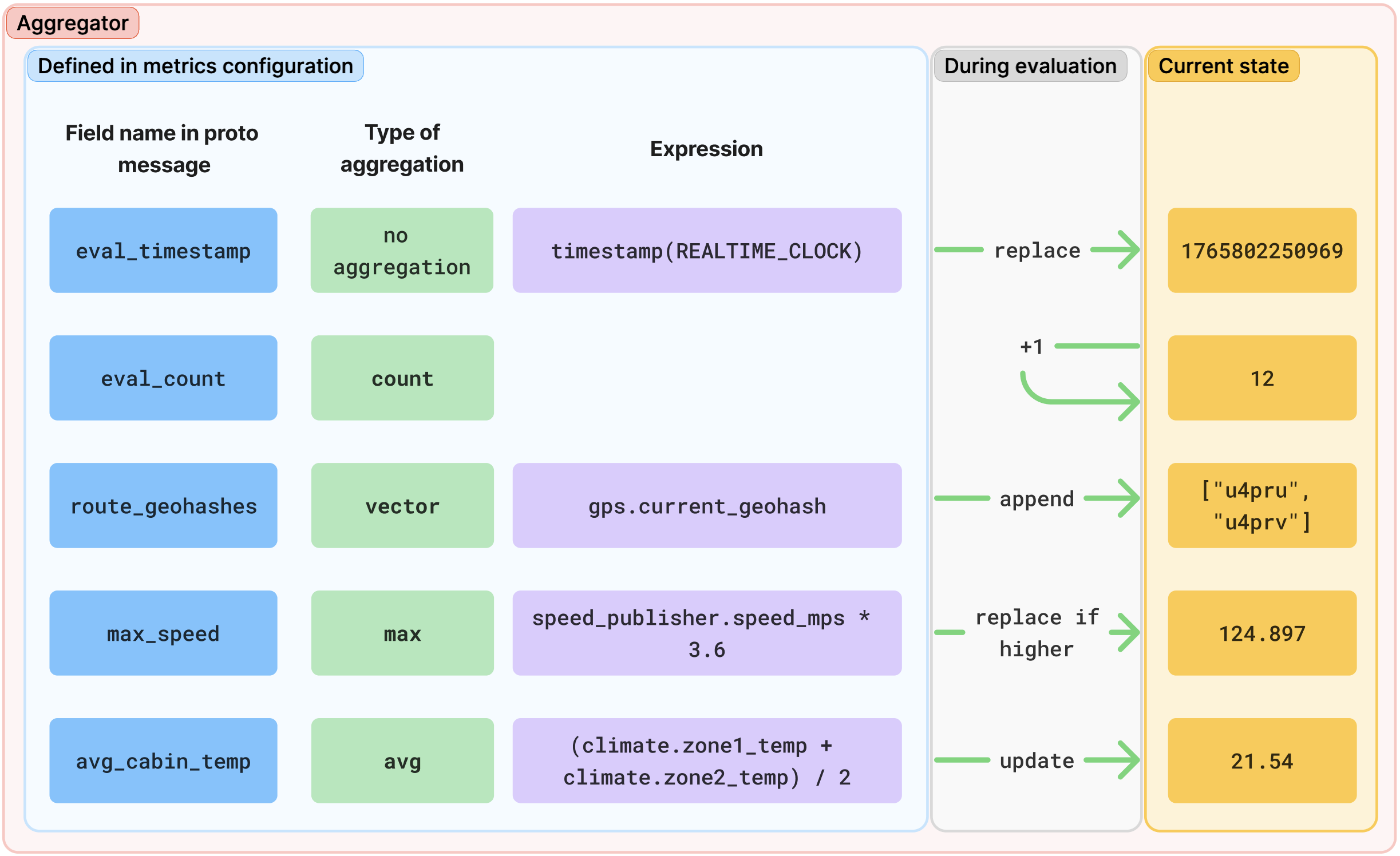
Rysunek 2. Ocena agregatora.
Przeprowadzanie obliczeń lub określanie warunków za pomocą wyrażeń
Wyrażenia są używane w narzędziach do tworzenia wiadomości i regułach warunkowych do wykonywania obliczeń lub określania warunków. Gdy używasz generatora konfiguracji danych (MCG) do tworzenia obiektów JSON konfiguracji danych, wyrażenia są zapisywane jako ciągi znaków zrozumiałe dla człowieka, które używają notacji kropkowej do uzyskiwania dostępu do pól źródła danych (np. vehicle_speed.speed_value) i stosowania szerokiego zakresu operacji. MCG tłumaczy te ciągi znaków na zoptymalizowaną strukturę drzewa, podobną do drzewa składni abstrakcyjnej (AST), aby umożliwić wydajną ocenę na urządzeniu w końcowej MetricsConfig wiadomości protobuf.
Operatory i funkcje
Wyrażenia obsługują ten zestaw operatorów i funkcji:
- Arytmetyka: obsługuje dodawanie, odejmowanie (dwuargumentowe i jednoargumentowe), mnożenie, dzielenie, modulo i potęgowanie.
- Logiczne: obsługuje operatory AND, OR, NOT i XOR.
- Relacyjne: obsługuje sprawdzanie równości oraz porównywanie wartości większych i mniejszych.
- Lista: sprawdza, czy lista zawiera określoną wartość.
- Sygnatura czasowa: zwraca sygnaturę czasową w momencie oceny w mikrosekundach. Typ zegara może być zegarem czasu rzeczywistego, czasem monotonicznym od uruchomienia (w tym czasem zawieszenia) lub czasem monotonicznym od uruchomienia lub ostatniego wznowienia.
- Wartość bezwzględna: zwraca wartość bezwzględną liczby.
- Zaokrąglanie: zaokrągla do najbliższej liczby całkowitej (
round), zwraca największą liczbę całkowitą mniejszą lub równą danej liczbie (floor) albo zwraca najmniejszą liczbę całkowitą większą lub równą danej liczbie (ceil).
Oto przykładowe wyrażenie, które odczytuje dane z 2 źródeł i zwraca wartość true, jeśli prędkość pojazdu przekracza 100 km/h i nie ma ostrzeżenia o ciśnieniu w oponach:
(vehicle_speed.speed_value * 3.6) > 100 && tire_pressure.warning == false
Sterowanie przepływem wykonywania za pomocą wyzwalaczy
Wywołania są elementami koordynującymi konfigurację danych; określają, kiedy dane są przetwarzane i kiedy generowane są raporty. Każdy wyzwalacz musi mieć unikalną nazwę.
Istnieją 3 rodzaje wyzwalaczy:
- Triggery danych: uruchamiają się, gdy źródło danych z połączeniem subskrypcji publikuje nową wiadomość (po próbkowaniu, jeśli zostało skonfigurowane).
- Okresowe wyzwalacze: uruchamiają się w stałych odstępach czasu.
- Reguły warunkowe: uruchamiają się, gdy zostanie spełniony określony warunek logiczny.
Aktywatory warunkowe
Reguły warunkowe nasłuchują innych reguł (danych, okresowych lub innych reguł warunkowych) i gdy jedna z nich zostanie uruchomiona, sprawdzają wyrażenie. Warunkowy warunek uruchamiający jest aktywowany tylko wtedy, gdy wynik wyrażenia spełnia określony warunek.
Możesz skonfigurować regułę warunkową tak, aby była uruchamiana na podstawie kilku typów warunków:
- Wartość: gdy wyrażenie przyjmuje wartość
true(lub inną niż zero) lubfalse(lub zero). - Zbocze narastające: gdy wyrażenie logiczne zmienia się z
falsenatruelub gdy wartość liczbowa rośnie. - Zbocze opadające: gdy wyrażenie logiczne zmienia się z
truenafalselub gdy wartość liczbowa maleje. - Po zmianie: gdy wynik wyrażenia różni się od jego poprzedniej wartości.
Filtrowanie zmian stanu powodujących szum
W przypadku wyzwalaczy opartych na zmianie stanu lub wyzwalanych przez zmianę stanu możesz odfiltrować krótkie lub zakłócone zmiany stanu (usterki), wymagając, aby warunek pozostawał w nowym stanie przez minimalny czas, zanim wyzwalacz zostanie uruchomiony.
Możesz na przykład skonfigurować regułę tak, aby uruchamiała się tylko wtedy, gdy warunek vehicle_speed > 100 zmieni się na true i pozostanie w tym stanie przez co najmniej 5 sekund.true Zapobiega to uruchomieniu
warunku z powodu chwilowego wzrostu prędkości odczytu. Możesz też wymagać, aby wszystkie wartości widoczne w tym okresie były dokładnie takie same.
Generowanie raportów o danych
Po przetworzeniu danych określasz, jak i kiedy mają być one pakowane w raporty.
Raporty są definiowane za pomocą konfiguracji raportów o danych, które używają narzędzi do tworzenia wiadomości, aby określić strukturę i treść danych wyjściowych. Gdy zostanie wywołany jeden z wyzwalaczy raportu, narzędzie do tworzenia wiadomości ocenia przypisania pól, aby utworzyć ładunek danych raportu.
Każdy wygenerowany raport jest instancją wiadomości Protobuf MetricsReport, która zawiera dane wyjściowe narzędzia do tworzenia wiadomości w polu payload i dodaje metadane. Usługa telemetrii automatycznie dodaje do każdego MetricsReport te metadane:
- Unikalny identyfikator uniwersalny (UUID) raportu.
- Numer porządkowy raportu, który zwiększa się w przypadku każdego raportu wygenerowanego przez tę konfigurację raportu.
- sygnatura czasowa wygenerowania raportu;
- Przyczyna wygenerowania (np. uruchomienie przez regułę lub wygenerowanie podczas zamykania)
- Identyfikator UUID i wersja konfiguracji danych, która wygenerowała raport.
- Nazwa konfiguracji raportu o rodzajach danych
Kontrola generowania raportów
Raporty są zwykle generowane w odpowiedzi na wyzwalacze, ale możesz też skonfigurować je tak, aby były generowane w określonych momentach cyklu życia konfiguracji danych:
- Raport o aktywacji: jeśli ta opcja jest włączona, system generuje wstępny raport natychmiast po aktywowaniu konfiguracji danych.
- Raport końcowy: jeśli ta opcja jest włączona, system generuje raport końcowy, gdy zbieranie danych zostanie wstrzymane lub zatrzymane albo gdy usługa telemetrii zostanie wyłączona. Ten raport zawiera dane zagregowane do tego momentu, co pomaga zapewnić, że na końcu sesji nie zostaną utracone żadne dane.
Zarządzanie cyklem życia zbierania danych
Domyślnie konfiguracja danych zaczyna zbierać i przetwarzać dane, gdy tylko zostanie aktywowana przez klienta, i kontynuuje to do momentu, gdy klient ją dezaktywuje. Możesz jednak bardziej szczegółowo kontrolować ten cykl życia, definiując wyzwalacze, które rozpoczynają lub zatrzymują zbieranie danych lub konfigurację rodzajów danych:
- Wywołanie rozpoczęcia: jeśli jest zdefiniowane, zbieranie danych rozpoczyna się dopiero po wywołaniu tego wywołania. Jeśli zbieranie zostało wstrzymane przez wyzwalacz zatrzymania, wyzwalacz rozpoczęcia wznawia je.
- Zatrzymanie wyzwalacza: jeśli jest zdefiniowany, ten wyzwalacz wstrzymuje zbieranie danych. Agregacje i generowanie raportów zostaną wstrzymane do momentu ponownego uruchomienia wyzwalacza.
- Dezaktywuj regułę: ta reguła dezaktywuje konfigurację danych w taki sam sposób jak wywołanie
deactivate_metrics_configz klienta.
Możesz na przykład zdefiniować wyzwalacz warunkowy, który uruchamia się, gdy vehicle_state zmieni się na DRIVING, jako wyzwalacz początkowy, a inny, który uruchamia się, gdy vehicle_state zmieni się na PARKED, jako wyzwalacz końcowy. Dzięki temu dane są zbierane tylko wtedy, gdy pojazd jest w ruchu.